HTTP Requests and Selenium
June 22, 2023 · 10 minute read
Introduction
BeautifulSoup in tandem with requests for general data collection and web scraping; and Selenium for more intricate projects that required increased interaction with web forms and dynamic elements.
HTTP Requests
I. Import Dependencies
GET request to the targeted web server, and BeautifulSoup to parse the HTML DOM.
import requests
from bs4 import BeautifulSoup
II. GET URL & Request Headers
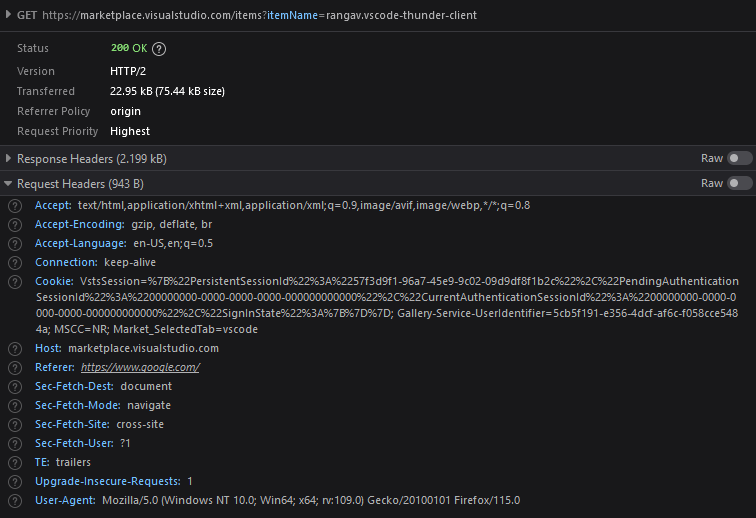
GET URL with the appropriate query parameters, as well as creating valid request headers to send to the target server. In most cases, you can easily append query parameters, denoted by a question mark in the url, to specify your targets. As for request headers, they are a part of the HTTP protocol and contain additional metadata information that is sent by the client to the server. This information provides information to the server and allows it to process the request correctly.
GET URL is extremely easy. An example can be seen below. In this case we are simply appending our query to facebook marketplace at the end of the URL.
query = input("Enter query: ")
url = "https://www.facebook.com/marketplace/104052009631991/search/?query={0}".format(query)
Accept-Encoding and Accept.
Accept-Encoding informs the server about acceptable encoding schemes that the client can handle for the response content. Having invalid values for this header may result in unreadable or malformed data from the server.
Accept indicates the content types or media types that the client is capable of understanding or processing. Typically for web scraping purposes this will be "application/json" or "text/html".
headersList = {
"Host": "www.facebook.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/114.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Alt-Used": "www.facebook.com",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"TE": "trailers"
}
III. Parsing HTML
response.text.
response = requests.get(url, headers=headersList)
soup = BeautifulSoup(response.text, 'html.parser')
find() and find_all() to help you extract data. More documentation on methods available to select elements can be found on the official documentation page.
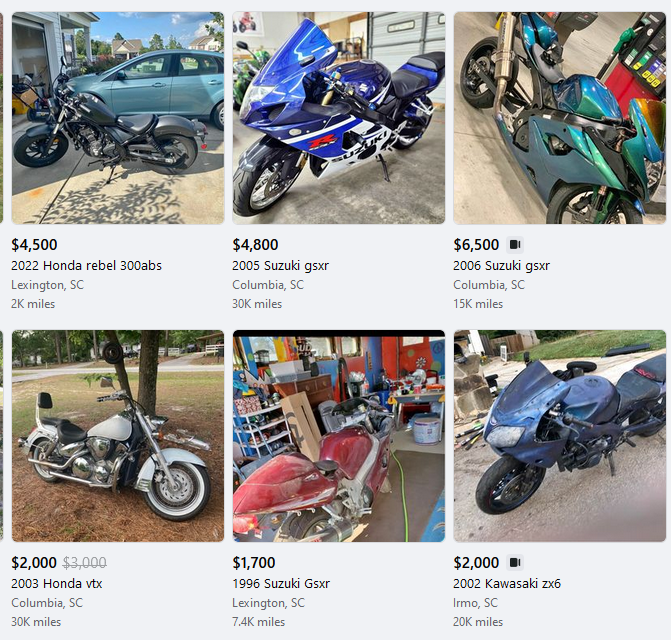
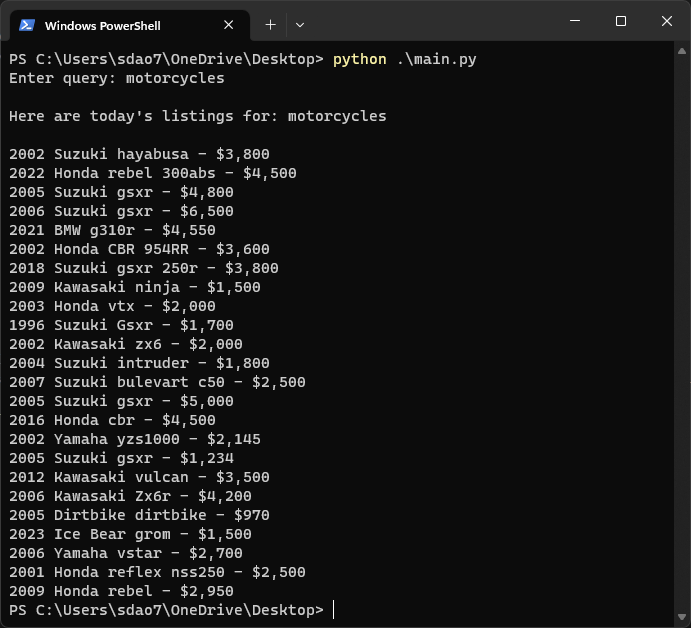
span elements with the class: x1lliihq x6ikm8r x10wlt62 x1n2onr6. This is because all span elements with this class contain the names of listings on the marketplace.
# Extracting data using BeautifulSoup's methods
#desired_data = soup.find_all('tag', class_='class_name')
names = soup.find_all("span", class_="x1lliihq x6ikm8r x10wlt62 x1n2onr6")
price = soup.find_all("span", class_="x193iq5w xeuugli x13faqbe x1vvkbs x1xmvt09 x1lliihq x1s928wv xhkezso x1gmr53x x1cpjm7i x1fgarty x1943h6x xudqn12 x676frb x1lkfr7t x1lbecb7 x1s688f xzsf02u")
for i in range(len(names)):
print("{0} - {1}".format(names[i].text, price[i].text))
Selenium
I. Getting Started
pip install selenium
import selenium
driver = selenium.webdriver.Chrome(executable_path='path/to/chromedriver')
webdriver_manager. THis module simplifies the process by automatically managing the installation and setup of the Chrome Driver binary.
webdriver_manager using pip:
pip install webdriver_manager
import selenium
from webdriver_manager.chrome import ChromeDriverManager
driver = selenium.webdriver.Chrome(service=selenium.webdriver.chrome.service.Service(executable_path=ChromeDriverManager().install()), options=options)
driver.get(targeted_url). Below is an example code snippet of searching google for the query, famous inventors.
import selenium
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
driver = selenium.webdriver.Chrome(service=selenium.webdriver.chrome.service.Service(executable_path=ChromeDriverManager().install()), options=options)
driver.get('www.google.com')
searchBar = driver.find_element(By.ID, "APjFqb")
submit = driver.find_element(By.NAME, "btnK")
searchBar.send_keys("famous inventors")
submit.click()
II. Selecting Elements
#Available selection methods
ID: element = driver.find_element(By.ID, "element_id")
CLASS: element = driver.find_element(By.CLASS_NAME, "element_class")
NAME: element = driver.find_element(By.NAME, "element_name")
TAG: element = driver.find_element(By.TAG_NAME, "tag name ie: span")
XPATH: element = driver.find_element(By.XPATH, "absolute or relative xpath")
iframe without first switching to that particular iframe. In this case, Selenium will throw an "Element not found" exception since it does not know to look inside of the iframe.
iframe
driver.switch_to.frame(iframe_element)
Explicit & Implicit Waits
ElementNotVisibleException.
import selenium
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
driver = selenium.webdriver.Chrome(service=selenium.webdriver.chrome.service.Service(executable_path=ChromeDriverManager().install()))
driver.get(URL)
#Explicitly wait Wait for the button to be clickable for a maximum of 10 seconds
button = WebDriverWait(driver, DURATION).until(expected_conditions.element_to_be_clickable((By.ID, "elementID")))
button = drvier.find_element(By.ID, "elementID")
button.click()
driver.quit()
import selenium
driver = selenium.webdriver.Chrome(service=selenium.webdriver.chrome.service.Service(executable_path=ChromeDriverManager().install()))
driver.get(URL)
#Set the implicit wait to ten seconds
driver.implicitly_wait(10)
button = driver.find_element(By.ID, "elementID")
button.click()
driver.quit()